Flink Tuning
Flink Parallelism
One of the best ways to ensure our Flink consumers/producers are optimised, is to align Flink parallelism to the number of Kafka partitions in our topics. This means that each thread will be producing or consuming to one partition. If on the other hand we have too many producers/consumers, they will compete for the partition, and if we have too few, some partitions will be unused.
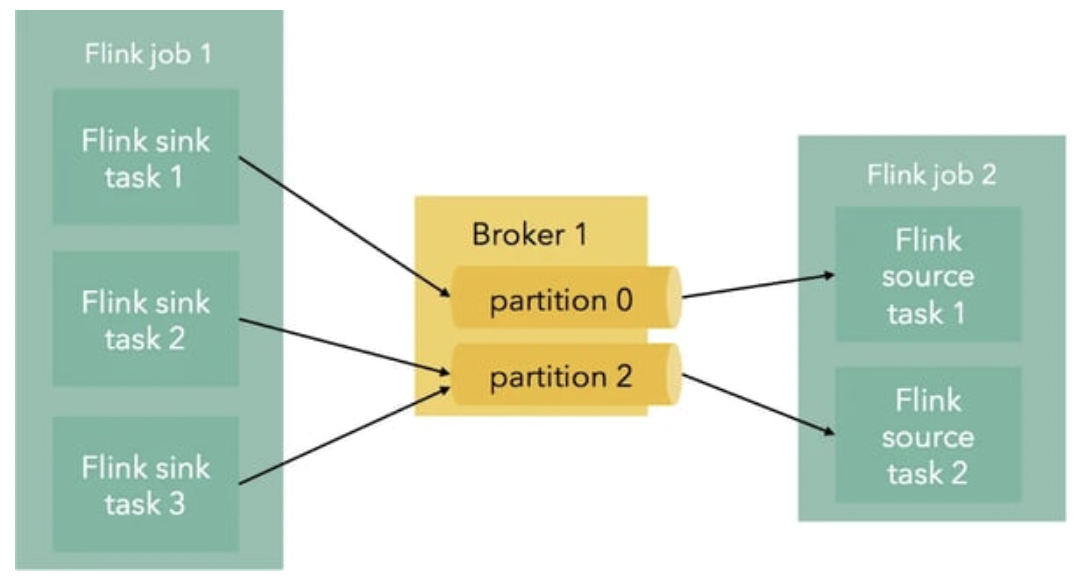
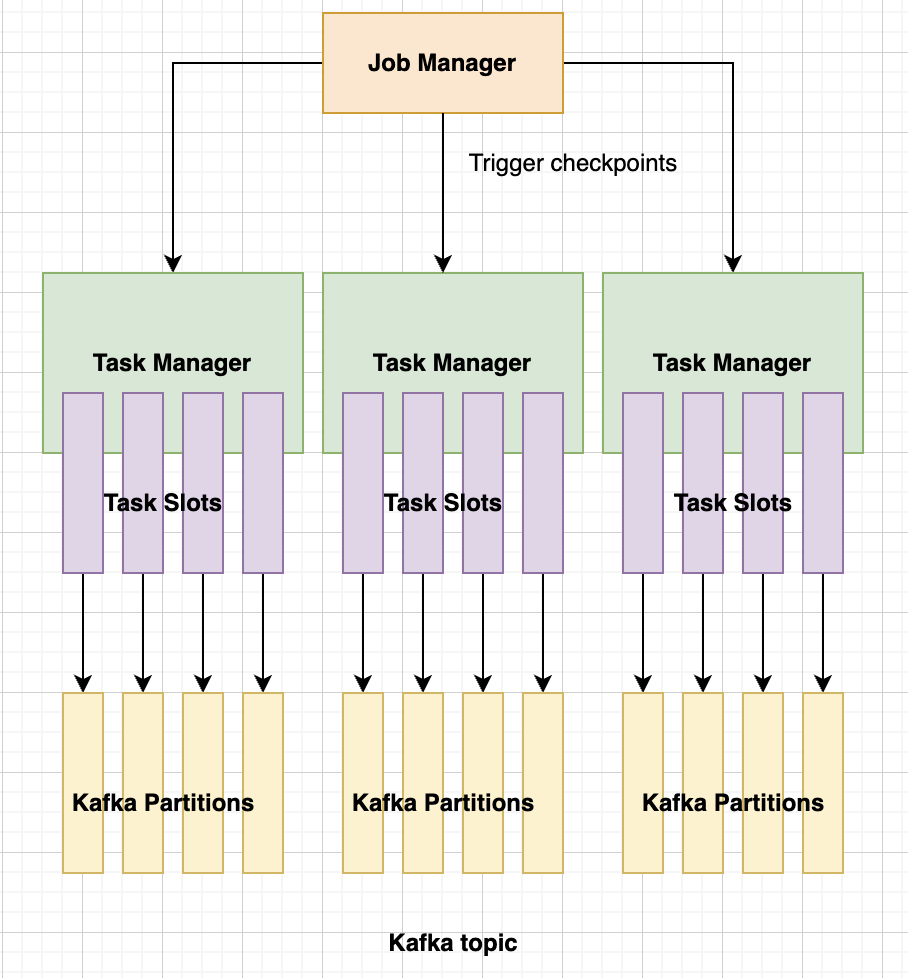
The ideal situation would therefore be to have one thread per partition. The calculations for one worker per thread:
Parallelism = numOfTaskManagers x numOfTaskSlots
So in this case, having 12 partitions in our topics, we could have 3 Task Managers with 4 slots each and a parallelism of 12. The properties for these in our configuration repos (values.yaml) are:
taskManager: replicas: 3taskmanager.numberOfTaskSlots: '4'jobConfig: parallelism: 12
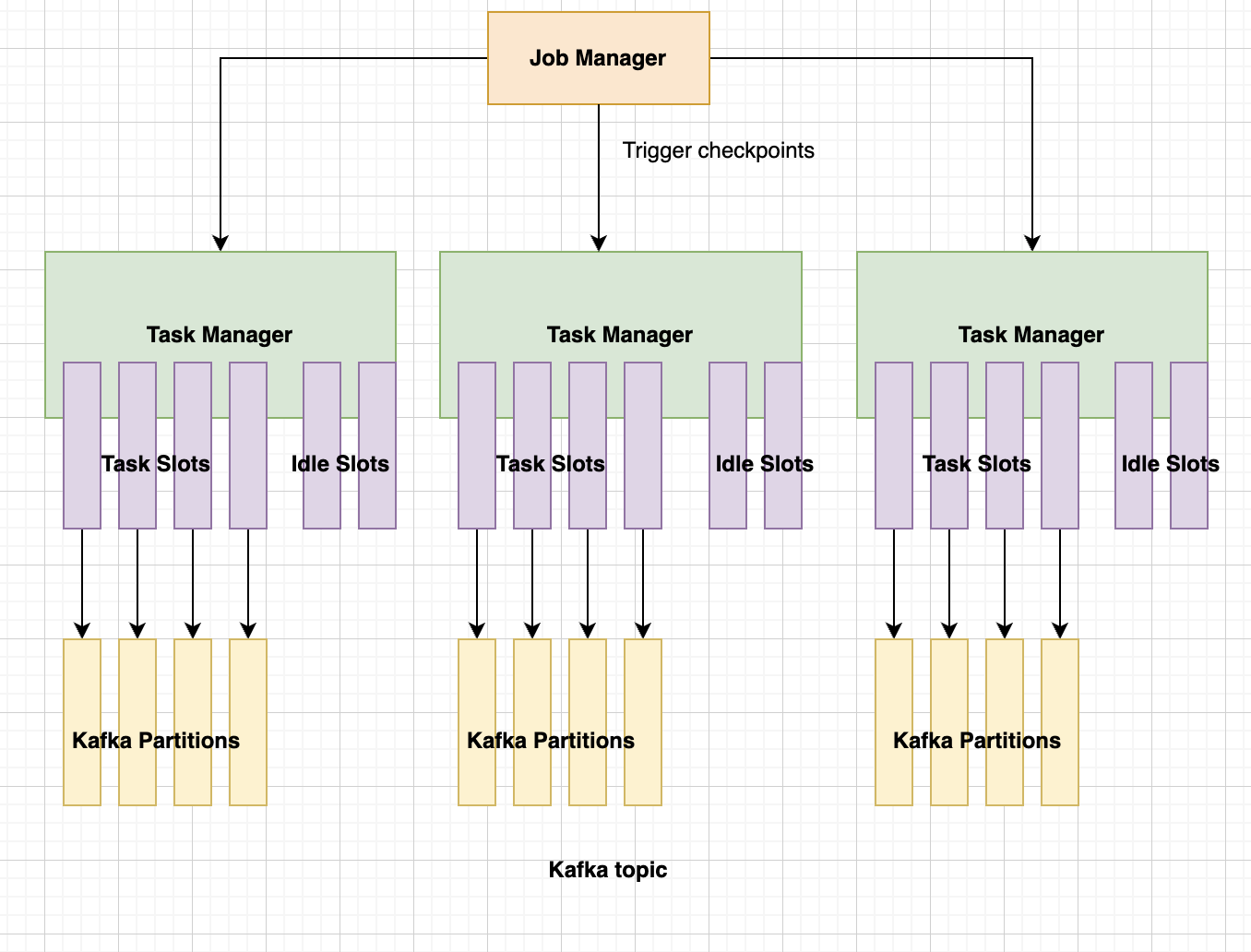
The only problem with this configuration is that if a Task Manager is restarted while we are processing activities, it will drop the threads it has, since the other Task Managers don't have any capacity for them. So if we want to increase resiliency, what we can do is add a higher number of task slots than parallelism, enough so that if we lose one Task Manager, the other can pick those threads up. For this use case, we could use the following configuration:
taskManager: replicas: 3taskmanager.numberOfTaskSlots: '6'jobConfig: parallelism: 12
Flink Checkpointing
There are a few different settings related to the checkpointing we can play with.
Flink Checkpointing Interval and Min Pause
By default, when a thread/task is doing a checkpoint, it will stop processing data until that checkpoint is completed. In a healthy Flink application, the time it takes to complete the checkpoints will be a lot less than the interval between checkpoints, ensuring there is some time left for processing data. When an operation is degraded, checkpoints take so long that there is no time to process data, which will massively affect performance and latencies.
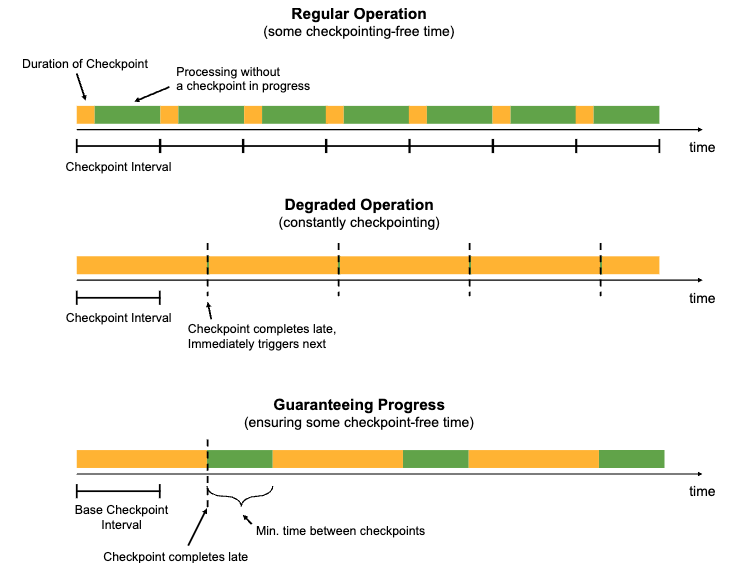
To prevent this, we have to carefully set the below values:
execution.checkpointing.interval: Indicates the interval between the start of two consecutive checkpoints.execution.checkpointing.min-pause: Optional but highly recommended. Indicates the minimum guaranteed pause between the end of a checkpoint and the beginning of the next one. This means that even if checkpointing took extremely long, we would still have windows in which our application is capable of processing data.
Full vs Incremental Checkpointing
This is controlled by the property state.backend.incremental: 'true' in our flinkConfiguration (values.yaml).
- Full checkpoints: Flink is taking a full snapshot of the current state
- Incremental checkpoins: Flink only saves the new changes since the last checkpoint. This takes a lot less time and resources.
Asynchronous and Unaligned checkpointing
By default, Flink uses aligned and synchronous checkpoints which means that all Flink workers will encounter checkpoint barriers during processing which signals the start of a checkpoint at the same time for all of them, and ensure a consistent state throughout operators. If an operator is slow or backpressured, other tasks must wait in the other operators, which increases checkpoint duration and can cause latency spikes. If we are concerned about consistency, this is the best option.
If on the other side, consistency is not as much of a problem and we want to improve latency and throughput, we can have a look into Asynchronous and Unaligned checkpointing:
- Asynchronous checkpointing: Checkpointing will happen on the background whilst we continue with our data processing.
- Unaligned checkpointing: Operators won't wait for each other. If one has finished checkpointing, it will continue processing without waiting for the other ones to finish.